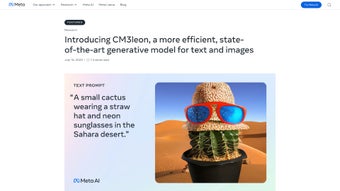
CM3leon: Model AI Multimodal Terdepan
CM3leon adalah model generatif terbaru yang memungkinkan pembuatan teks dan gambar secara bersamaan. Dengan kemampuan untuk menghasilkan gambar dari teks dan sebaliknya, model ini menggabungkan efisiensi pelatihan dan inferensi yang rendah. Menggunakan teknik pelatihan canggih, CM3leon menunjukkan kinerja luar biasa dalam berbagai tugas, termasuk pembuatan caption gambar dan pertanyaan visual.
Alternatif yang Direkomendasikan Teratas
Model ini tidak hanya unggul dalam menghasilkan gambar yang koheren berdasarkan input tetapi juga dalam mengedit gambar yang dipandu teks. Dengan skor Fréchet Inception Distance (FID) yang mengesankan, CM3leon mengalahkan model-model sebelumnya, termasuk dari Google. Berkat kemampuannya dalam mengatasi kompleksitas objek dan struktur komposisi, model ini menjadi alat yang sangat berharga untuk tugas-tugas yang menggabungkan visi dan bahasa.